SLAM 算法分析¶
SLAM 14讲¶
目标¶
- 用Nsight Tegra 来分析每一个例子瓶颈
- 用LLVM 生成callgraph, 如何查看其编译的参数
- 找出各种优化方法
- 并且写出验证代码
- 写出自动优化的框架
- 生成各种report
- 实现debug过程的可视化,可以通过扩展gdb,以及底层的api为一些动态的数据。
ch4 使用李群与李代数¶
由旋转矩阵是李群,然后通过李代数的映射来计算旋转矩阵。相似变换也是李群。
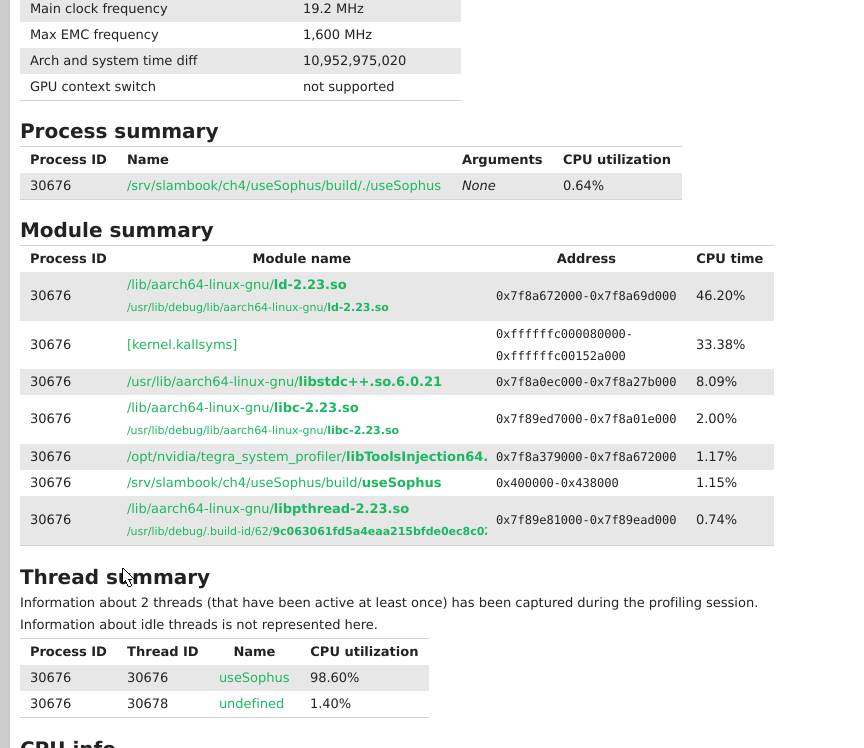
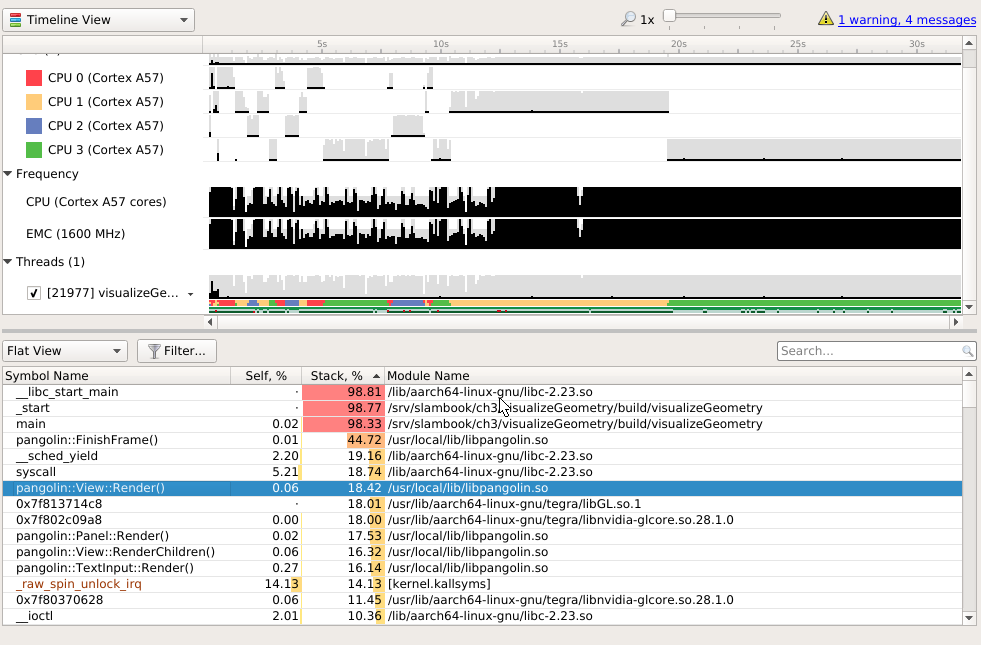
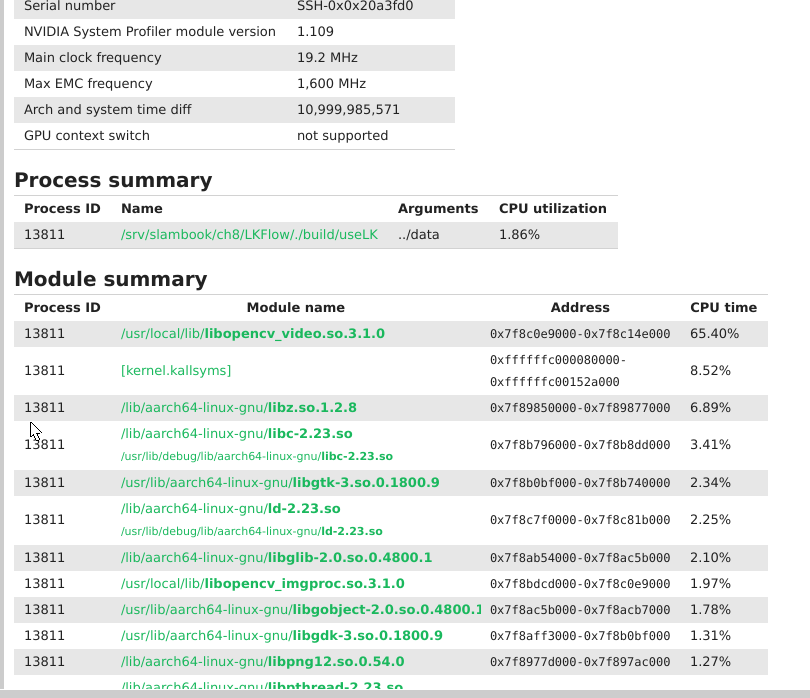
useSophus 的profiling分析
- 由于helloworld级的代码,大部分CPU时间都花在了ld-2.23.0 再查其callstack大部分时间花在了 dl_lookup_symbol_x 这个函数。 dl_lookup_symbols_x 是glib C runtime 库,用来查动态链接库中的符号查询。 解决见 stackowerflow
- 真正profiling算法本身的性能时,可能就要代码中加入一些mark标记,这样才能准确的profiling. 或者在profiling时加入一定等待时间。
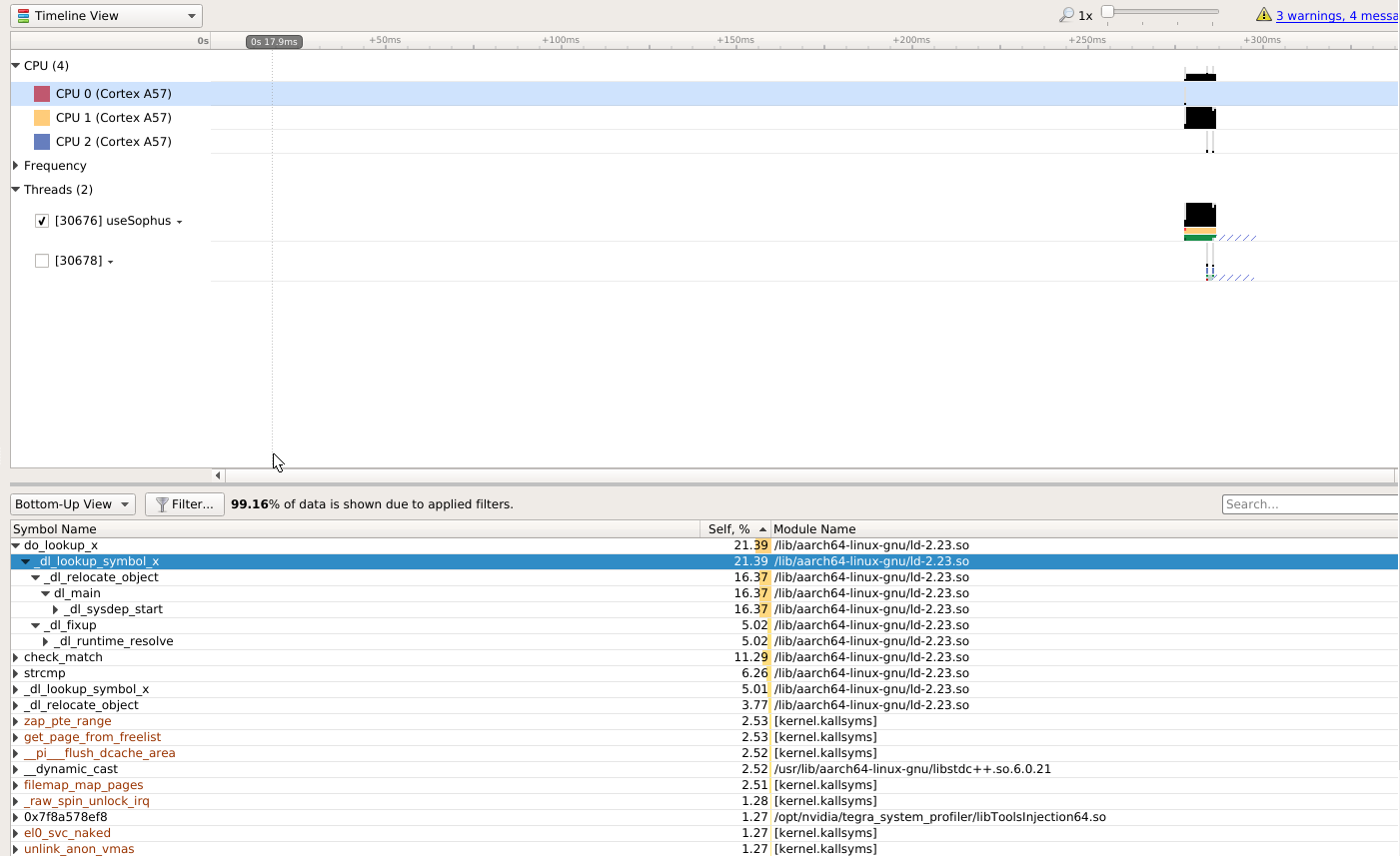
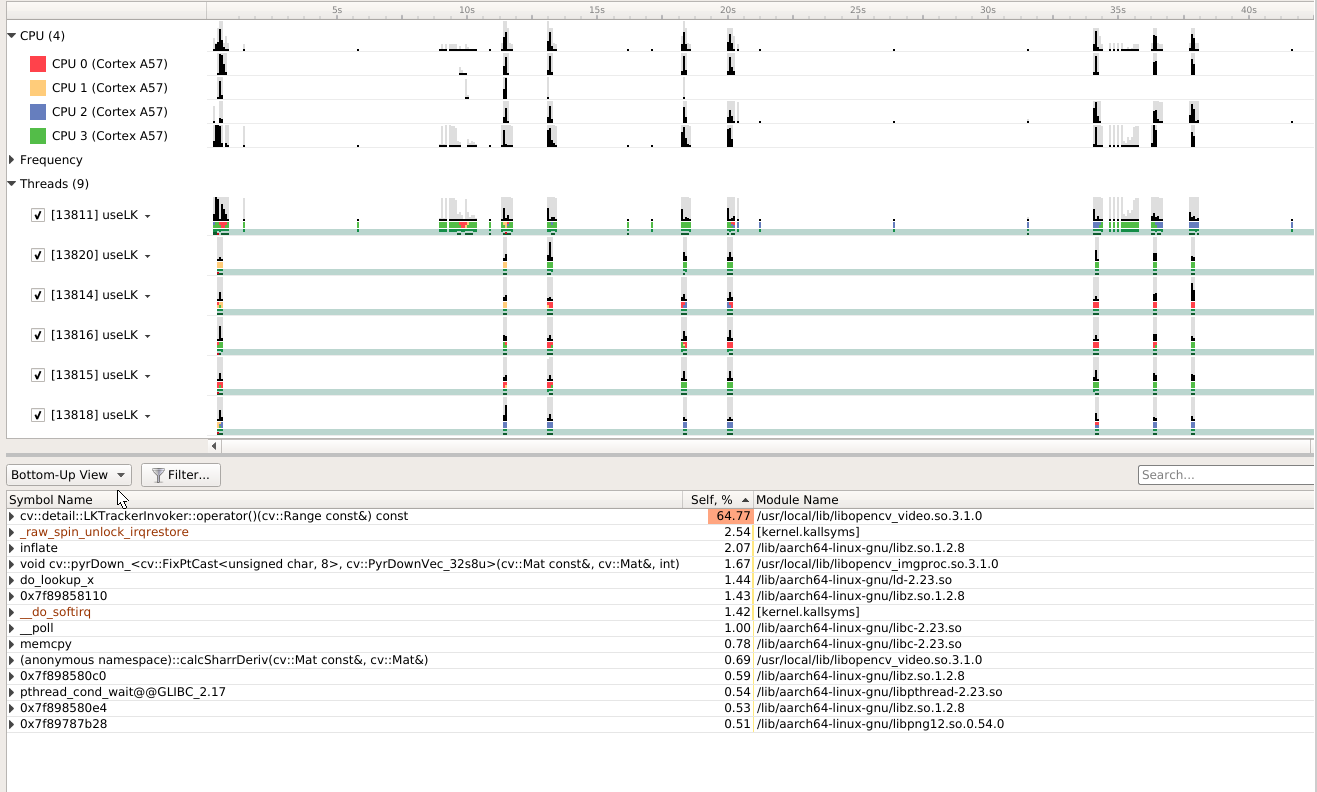
useSophus 的timeline
- 看起来基本是单线程也没有跑满。
CH5相机与图像¶
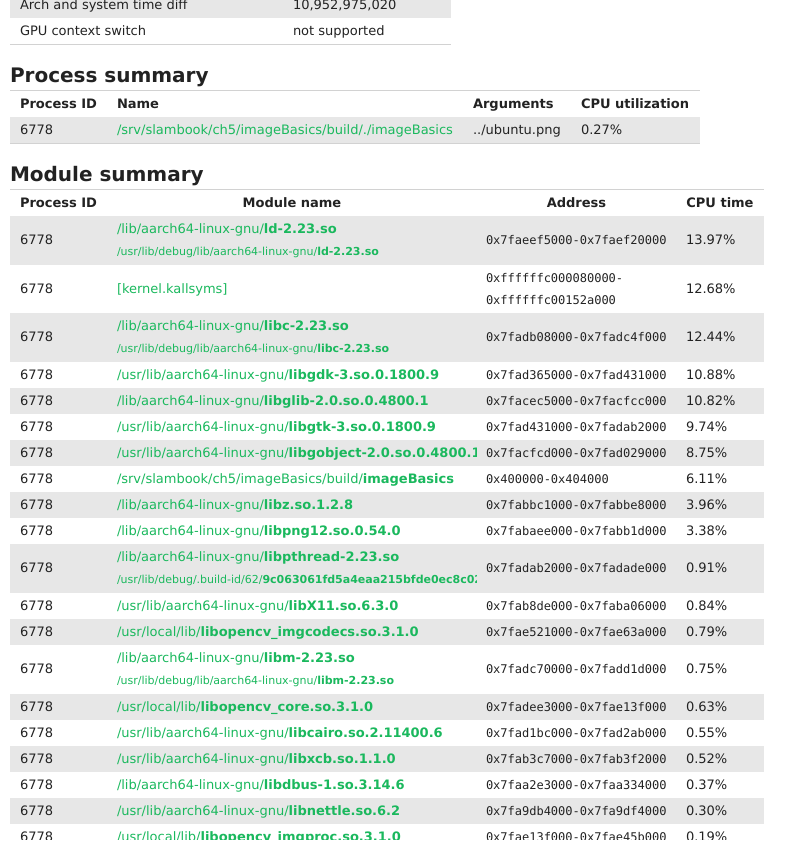
imageBasics
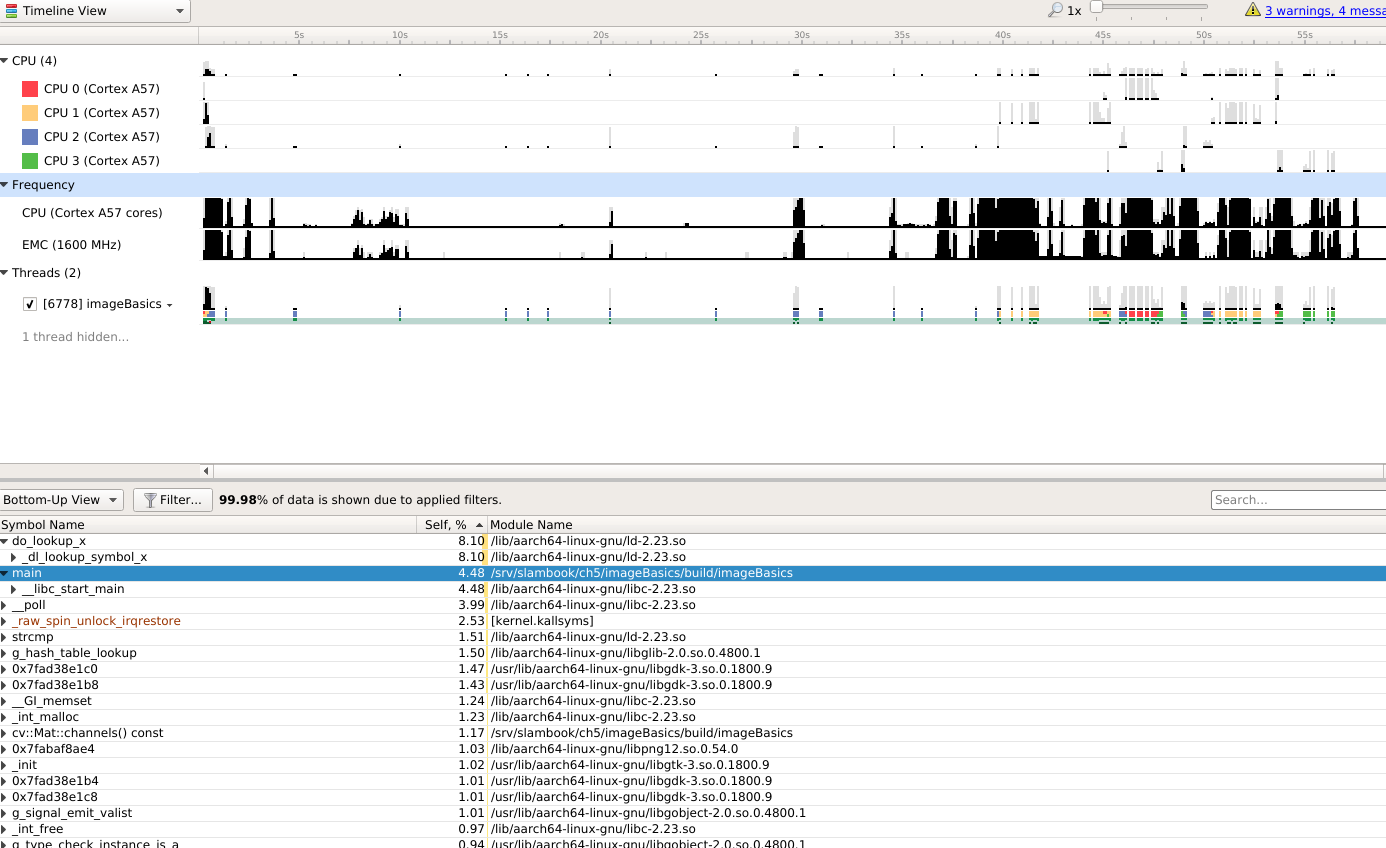
imageBasics timeline
从上面的图中可以看到,一个单线程的进程,却发生了几次 thread context的切换。并且每一次的 切换也都耗费了两分钟。
当不是很规范的时候,例如一个大函数搞定一切,如果想进一步了解性能原因,那就要用到 nvtx来标记了,或者支持源码级的优化,也就是每一个行指令的执行的次数,或者利用 颜色标记出来,例如颜色越深的地方,也就是执行次数最多的地方。当然就需要instruction 级别的profiling了。
同时利用脚本来执行这些profiling最后集中查看会更加方便。 甚至一个整套的profiling测试 修改源码,编译,执行profiling测试,并且根据profiling的数据生成测试分析报告图表。
同时在一个机器编译的binary,如何快速复制其他device上也能跑呢,并且其又依赖大量的库。 一个个机器去装这些依赖库也挺麻烦的。 一个快速的方法那就是 直接用ldd 把 每一个binary 的依赖的 so 打包。然后再加上LD_PRELOAD来加载,这样就可以加快部署的进程。 例外一种还需要多线程的操作,可能需要同时操作两条线。例如
- 一个线程要操作 binary本身
- 另一个线程要操作 profiling等等。
位姿记录的形式是平移向量旋转四元数: \([x,y,z,q_x,q_y,q_z,q_w]\)
而生成地图的格式 PCL pcd file format
ch6 非线优化¶
Ceres¶
用法用核心就是 定义loss函数。 然后用把数据扔给solver就行了。
看一个hello world就明白了。
struct CostFunctor {
template <typename T>
bool operator()(const T* const x, T* residual) const {
residual[0] = T(10.0) - x[0];
return true;
}
};
int main(int argc, char** argv) {
google::InitGoogleLogging(argv[0]);
// The variable to solve for with its initial value.
double initial_x = 5.0;
double x = initial_x;
// Build the problem.
Problem problem;
// Set up the only cost function (also known as residual). This uses
// auto-differentiation to obtain the derivative (jacobian).
CostFunction* cost_function =
new AutoDiffCostFunction<CostFunctor, 1, 1>(new CostFunctor);
problem.AddResidualBlock(cost_function, NULL, &x);
// Run the solver!
Solver::Options options;
options.linear_solver_type = ceres::DENSE_QR;
options.minimizer_progress_to_stdout = true;
Solver::Summary summary;
Solve(options, &problem, &summary);
std::cout << summary.BriefReport() << "\n";
std::cout << "x : " << initial_x
<< " -> " << x << "\n";
return 0;
}
g2o¶
图优化的目标就是把用优化问题变成图优。
优化问题 \(\min\limits_{x} F(x)\) 三个基本因素:
- 目标函数
- 优化变量
- 优化约束
最基本的图优化就是用图模型来表达一个非线性最小二乘的优化问题。
图优化的原理 在图中,以顶点表示优化变量,以边表示观测方程或者边为误差项。 我们目标最短路径 或者全体权值最小。
在图中,我们去掉孤立顶点或化先优化边数较多的顶点。
与ceres 类似,这个是一个通用优化框架,你需要继承或定义问题本身的基本模型就可以了。 例如g2o就是要定义顶点类与边类的如何更新与计算。 把一堆的顶点与边扔进去。
ch7 VO¶
feature_exection¶
特征点的提取与描述子两部分组成。 特征点的提取计算与以及有准备性。


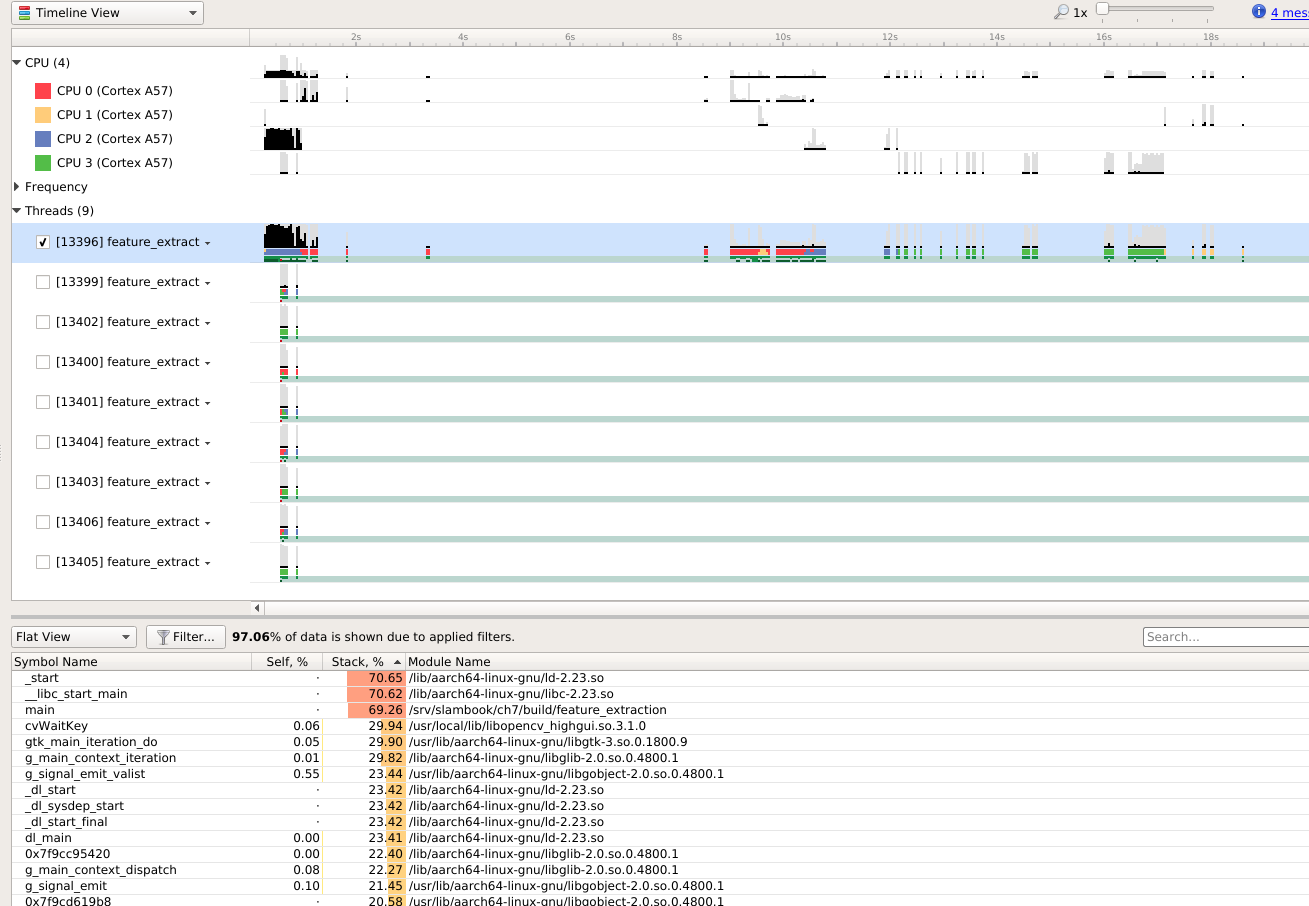
|
comments | ||
| SIFT | |||
| FAST | |||
| ORB | Oriented FAST and Rotateed BRIEF |
1000 个字, ORB 15.3ms, SURF,217.3ms, SIFT 5228.7ms.
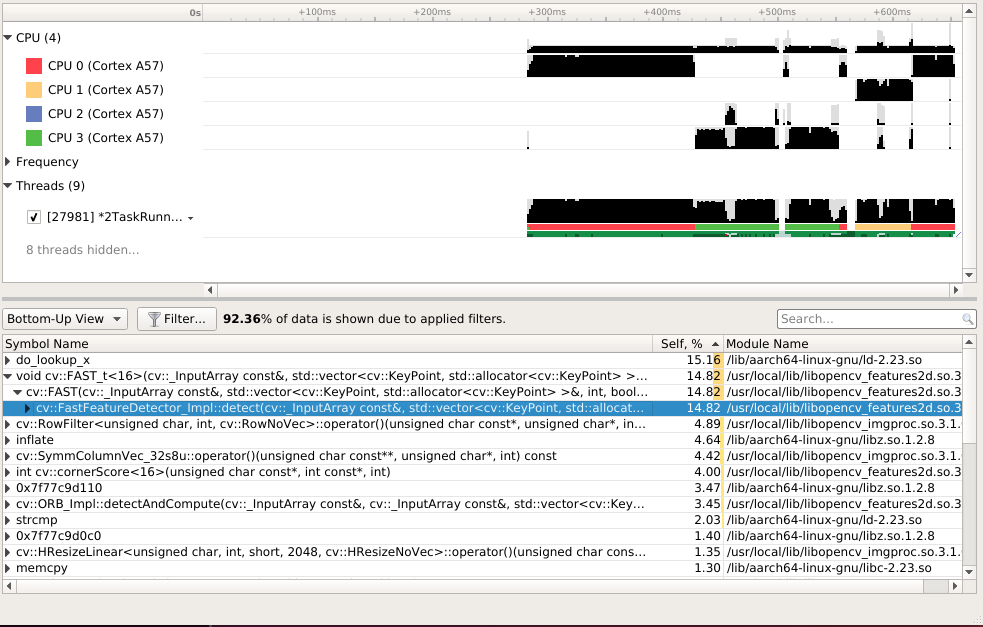
ch8 V0¶
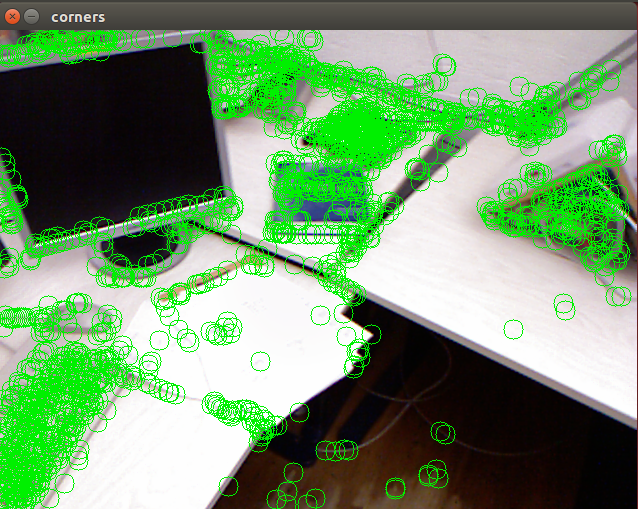
DirectSemiDense and DirectSparse¶
Buserror wait for debug,这个是由 Trace/breakpoint Trap signal引起的,直接gdb时,gdb也直接发挂那。
Using host libthread_db library "/lib/aarch64-linux-gnu/libthread_db.so.1".
*********** loop 0 ************
[New Thread 0x7fa7430db0 (LWP 9961)]
[New Thread 0x7fa6c30db0 (LWP 9962)]
[New Thread 0x7fa6430db0 (LWP 9963)]
[New Thread 0x7fa5c30db0 (LWP 9964)]
[New Thread 0x7fa5430db0 (LWP 9965)]
[New Thread 0x7fa4c30db0 (LWP 9966)]
[New Thread 0x7f8fffedb0 (LWP 9967)]
[New Thread 0x7f8f7fedb0 (LWP 9968)]
add total 12556 measurements.
*********** loop 1 ************
edges in graph: 12556
iteration= 0 chi2= 72633591.401419 time= 0.735174 cumTime= 0.735174 edges= 12556 schur= 0 lambda= 12900954.939934 levenbergIter= 1
iteration= 1 chi2= 62926900.131419 time= 0.739193 cumTime= 1.47437 edges= 12556 schur= 0 lambda= 4300318.313311 levenbergIter= 1
iteration= 2 chi2= 52845484.671121 time= 0.736138 cumTime= 2.2105 edges= 12556 schur= 0 lambda= 1433439.437770 levenbergIter= 1
iteration= 3 chi2= 45449292.558261 time= 0.733896 cumTime= 2.9444 edges= 12556 schur= 0 lambda= 477813.145923 levenbergIter= 1
iteration= 4 chi2= 38422805.114205 time= 0.744241 cumTime= 3.68864 edges= 12556 schur= 0 lambda= 159271.048641 levenbergIter= 1
iteration= 5 chi2= 31970398.890953 time= 0.74077 cumTime= 4.42941 edges= 12556 schur= 0 lambda= 53090.349547 levenbergIter= 1
iteration= 6 chi2= 24270565.530351 time= 0.732403 cumTime= 5.16182 edges= 12556 schur= 0 lambda= 17696.783182 levenbergIter= 1
iteration= 7 chi2= 12153446.174612 time= 0.73939 cumTime= 5.9012 edges= 12556 schur= 0 lambda= 5898.927727 levenbergIter= 1
iteration= 8 chi2= 5615434.148147 time= 0.74188 cumTime= 6.64308 edges= 12556 schur= 0 lambda= 1966.309242 levenbergIter= 1
iteration= 9 chi2= 4849512.586059 time= 0.733603 cumTime= 7.37669 edges= 12556 schur= 0 lambda= 655.436414 levenbergIter= 1
iteration= 10 chi2= 4785381.917957 time= 0.733941 cumTime= 8.11063 edges= 12556 schur= 0 lambda= 218.478805 levenbergIter= 1
iteration= 11 chi2= 4785319.436062 time= 0.740044 cumTime= 8.85067 edges= 12556 schur= 0 lambda= 145.652536 levenbergIter= 1
iteration= 12 chi2= 4785319.043803 time= 1.63759 cumTime= 10.4883 edges= 12556 schur= 0 lambda= 1708231013067781.250000 levenbergIter= 10
The program being debugged has been started already.
Start it from the beginning? (y or n) y
Starting program: /srv/slambook/ch8/directMethod/build/direct_semidense data
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/aarch64-linux-gnu/libthread_db.so.1".
*********** loop 0 ************
[New Thread 0x7fa7430db0 (LWP 5767)]
[New Thread 0x7fa6c30db0 (LWP 5768)]
[New Thread 0x7fa6430db0 (LWP 5769)]
[New Thread 0x7fa5c30db0 (LWP 5770)]
[New Thread 0x7fa5430db0 (LWP 5771)]
[New Thread 0x7fa4c30db0 (LWP 5772)]
[New Thread 0x7f8fffedb0 (LWP 5773)]
[New Thread 0x7f8f7fedb0 (LWP 5774)]
add total 12556 measurements.
*********** loop 1 ************
edges in graph: 12556
Thread 1 "direct_semidens" hit Breakpoint 2, poseEstimationDirect (measurements=std::vector of length 12556, capacity 16384 = {...}, gray=0x7fffffeef8, K=..., Tcw=...)
at /srv/slambook/ch8/directMethod/direct_semidense.cpp:294
294 optimizer.optimize ( 30 );
(gdb) b g2o::SparseOptimizer::optimize
/build/gdb-qLNsm9/gdb-7.11.1/gdb/aarch64-tdep.c:334: internal-error: aarch64_analyze_prologue: Assertion `inst.operands[0].type == AARCH64_OPND_Rt' failed.
A problem internal to GDB has been detected,
further debugging may prove unreliable.
Quit this debugging session? (y or n)
Please answer y or n.
/build/gdb-qLNsm9/gdb-7.11.1/gdb/
进一步调试发现gdb也有问题,这时候基本挂在 return result上。
operator Isometry3D() const ¦
¦288 { ¦
¦289 Isometry3D result = (Isometry3D) rotation(); ¦
¦290 result.translation() = translation(); ¦
>¦291 return result; k::now(); ¦
¦292 }
0x537838 <g2o::SE3Quat::operator Eigen::Transform<double, 3, 1, 0>() const+92> str x0, [sp]
x0 0x7fffffdf18 549755805464
x29 0x7fffffdf40 549755805504
sp 0x7fffffdef0 0x7fffffdef0
同时进一步发现g2o 的优化时 lamda 异常提前退出
[New Thread 0x7f8fffedb0 (LWP 5718)]
[New Thread 0x7f8f7fedb0 (LWP 5719)]
add total 12556 measurements.
*********** loop 1 ************
edges in graph: 12556
Thread 1 "direct_semidens" hit Breakpoint 2, poseEstimationDirect (measurements=std::vector of length 12556, capacity 16384 = {...}, gray=0x7fffffeef8, K=..., Tcw=...)
at /srv/slambook/ch8/directMethod/direct_semidense.cpp:294
294 optimizer.optimize ( 30 );
(gdb) s optimizer.optimize(10)
Couldn't find method g2o::SparseOptimizer::optimize
/usr/local/include/g2o/core/base_unary_edge.h, /usr/local/include/g2o/core/base_edge.h, /usr/include/c++/5/bits/stl_set.h, /usr/include/c++/5/bits/ptr_traits.h,
/usr/local/include/g2o/core/sparse_block_matrix_diagonal.h, /usr/local/include/g2o/core/block_solver.h, /usr/include/c++/5/bits/unordered_map.h, /usr/include/c++/5/bits/hashtable.h,
/usr/include/c++/5/utility, /usr/include/c++/5/bits/functional_hash.h, /usr/include/c++/5/bits/hashtable_policy.h, /usr/local/include/g2o/core/sparse_block_matrix_ccs.h,
/usr/include/c++/5/bits/stl_map.h, /usr/include/c++/5/bits/stl_function.h, /usr/include/c++/5/ext/aligned_buffer.h, /usr/local/include/g2o/core/sparse_block_matrix.h,
/usr/local/include/g2o/core/linear_solver.h, /usr/include/c++/5/chrono, /usr/include/c++/5/bits/stl_iterator_base_types.h, /usr/include/c++/5/bits/stl_iterator.h, /usr/include/c++/5/bits/stl_algo.h,
---Type <return> to continue, or q <return> to quit---q
/usrQuit
(gdb) b g2o::SparseOptimizer::optimize
/build/gdb-qLNsm9/gdb-7.11.1/gdb/aarch64-tdep.c:334: internal-error: aarch64_analyze_prologue: Assertion `inst.operands[0].type == AARCH64_OPND_Rt' failed.
A problem internal to GDB has been detected,
further debugging may prove unreliable.
Quit this debugging session? (y or n) y
//gdb source code
/* Analyze a prologue, looking for a recognizable stack frame
and frame pointer. Scan until we encounter a store that could
clobber the stack frame unexpectedly, or an unknown instruction. */
static CORE_ADDR
aarch64_analyze_prologue (struct gdbarch *gdbarch,
CORE_ADDR start, CORE_ADDR limit,
struct aarch64_prologue_cache *cache)
{
enum bfd_endian byte_order_for_code = gdbarch_byte_order_for_code (gdbarch);
int i;
pv_t regs[AARCH64_X_REGISTER_COUNT];
struct pv_area *stack;
struct cleanup *back_to;
for (i = 0; i < AARCH64_X_REGISTER_COUNT; i++)
regs[i] = pv_register (i, 0);
stack = make_pv_area (AARCH64_SP_REGNUM, gdbarch_addr_bit (gdbarch));
back_to = make_cleanup_free_pv_area (stack);
for (; start < limit; start += 4)
{
uint32_t insn;
aarch64_inst inst;
insn = read_memory_unsigned_integer (start, 4, byte_order_for_code);
if (aarch64_decode_insn (insn, &inst, 1) != 0)
break;
if (inst.opcode->iclass == addsub_imm
&& (inst.opcode->op == OP_ADD
|| strcmp ("sub", inst.opcode->name) == 0))
{
unsigned rd = inst.operands[0].reg.regno;
unsigned rn = inst.operands[1].reg.regno;
gdb_assert (aarch64_num_of_operands (inst.opcode) == 3);
gdb_assert (inst.operands[0].type == AARCH64_OPND_Rd_SP);
gdb_assert (inst.operands[1].type == AARCH64_OPND_Rn_SP);
gdb_assert (inst.operands[2].type == AARCH64_OPND_AIMM);
if (inst.opcode->op == OP_ADD)
{
regs[rd] = pv_add_constant (regs[rn],
inst.operands[2].imm.value);
}
else
{
regs[rd] = pv_add_constant (regs[rn],
-inst.operands[2].imm.value);
}
}
else if (inst.opcode->iclass == pcreladdr
&& inst.operands[1].type == AARCH64_OPND_ADDR_ADRP)
{
gdb_assert (aarch64_num_of_operands (inst.opcode) == 2);
gdb_assert (inst.operands[0].type == AARCH64_OPND_Rd);
regs[inst.operands[0].reg.regno] = pv_unknown ();
}
else if (inst.opcode->iclass == branch_imm)
{
/* Stop analysis on branch. */
break;
}
else if (inst.opcode->iclass == condbranch)
{
/* Stop analysis on branch. */
break;
}
else if (inst.opcode->iclass == branch_reg)
{
/* Stop analysis on branch. */
break;
}
else if (inst.opcode->iclass == compbranch)
{
/* Stop analysis on branch. */
break;
}
else if (inst.opcode->op == OP_MOVZ)
{
gdb_assert (inst.operands[0].type == AARCH64_OPND_Rd);
regs[inst.operands[0].reg.regno] = pv_unknown ();
}
else if (inst.opcode->iclass == log_shift
&& strcmp (inst.opcode->name, "orr") == 0)
{
unsigned rd = inst.operands[0].reg.regno;
unsigned rn = inst.operands[1].reg.regno;
unsigned rm = inst.operands[2].reg.regno;
gdb_assert (inst.operands[0].type == AARCH64_OPND_Rd);
gdb_assert (inst.operands[1].type == AARCH64_OPND_Rn);
gdb_assert (inst.operands[2].type == AARCH64_OPND_Rm_SFT);
if (inst.operands[2].shifter.amount == 0
&& rn == AARCH64_SP_REGNUM)
regs[rd] = regs[rm];
else
{
if (aarch64_debug)
{
debug_printf ("aarch64: prologue analysis gave up "
"addr=0x%s opcode=0x%x (orr x register)\n",
core_addr_to_string_nz (start), insn);
}
break;
}
}
else if (inst.opcode->op == OP_STUR)
{
unsigned rt = inst.operands[0].reg.regno;
unsigned rn = inst.operands[1].addr.base_regno;
int is64
= (aarch64_get_qualifier_esize (inst.operands[0].qualifier) == 8);
gdb_assert (aarch64_num_of_operands (inst.opcode) == 2);
gdb_assert (inst.operands[0].type == AARCH64_OPND_Rt);
gdb_assert (inst.operands[1].type == AARCH64_OPND_ADDR_SIMM9);
gdb_assert (!inst.operands[1].addr.offset.is_reg);
pv_area_store (stack, pv_add_constant (regs[rn],
inst.operands[1].addr.offset.imm),
is64 ? 8 : 4, regs[rt]);
}
else if ((inst.opcode->iclass == ldstpair_off
|| inst.opcode->iclass == ldstpair_indexed)
&& inst.operands[2].addr.preind
&& strcmp ("stp", inst.opcode->name) == 0)
{
unsigned rt1 = inst.operands[0].reg.regno;
unsigned rt2 = inst.operands[1].reg.regno;
unsigned rn = inst.operands[2].addr.base_regno;
int32_t imm = inst.operands[2].addr.offset.imm;
gdb_assert (inst.operands[0].type == AARCH64_OPND_Rt);
gdb_assert (inst.operands[1].type == AARCH64_OPND_Rt2);
gdb_assert (inst.operands[2].type == AARCH64_OPND_ADDR_SIMM7);
gdb_assert (!inst.operands[2].addr.offset.is_reg);
/* If recording this store would invalidate the store area
(perhaps because rn is not known) then we should abandon
further prologue analysis. */
if (pv_area_store_would_trash (stack,
pv_add_constant (regs[rn], imm)))
break;
if (pv_area_store_would_trash (stack,
pv_add_constant (regs[rn], imm + 8)))
break;
pv_area_store (stack, pv_add_constant (regs[rn], imm), 8,
regs[rt1]);
pv_area_store (stack, pv_add_constant (regs[rn], imm + 8), 8,
regs[rt2]);
if (inst.operands[2].addr.writeback)
regs[rn] = pv_add_constant (regs[rn], imm);
}
else if (inst.opcode->iclass == testbranch)
{
/* Stop analysis on branch. */
break;
}
else
{
if (aarch64_debug)
{
debug_printf ("aarch64: prologue analysis gave up addr=0x%s"
" opcode=0x%x\n",
core_addr_to_string_nz (start), insn);
}
break;
}
}
if (cache == NULL)
{
do_cleanups (back_to);
return start;
}
if (pv_is_register (regs[AARCH64_FP_REGNUM], AARCH64_SP_REGNUM))
{
/* Frame pointer is fp. Frame size is constant. */
cache->framereg = AARCH64_FP_REGNUM;
cache->framesize = -regs[AARCH64_FP_REGNUM].k;
}
else if (pv_is_register (regs[AARCH64_SP_REGNUM], AARCH64_SP_REGNUM))
{
/* Try the stack pointer. */
cache->framesize = -regs[AARCH64_SP_REGNUM].k;
cache->framereg = AARCH64_SP_REGNUM;
}
else
{
/* We're just out of luck. We don't know where the frame is. */
cache->framereg = -1;
cache->framesize = 0;
}
for (i = 0; i < AARCH64_X_REGISTER_COUNT; i++)
{
CORE_ADDR offset;
if (pv_area_find_reg (stack, gdbarch, i, &offset))
cache->saved_regs[i].addr = offset;
}
do_cleanups (back_to);
return start;
}
实质上采用的是 levenbergIter迭代法,遇到这种问题,就要看返回的对象是不是对,是不是因为未定状态,造成stackoverflow,从而引发的 trap的signal. 例如返回的result的值是否合法。
因为 aarch64 中 x29 就是Framepointer. http://infocenter.arm.com/help/topic/com.arm.doc.ihi0055b/IHI0055B_aapcs64.pdf
0x537838 <g2o::SE3Quat::operator Eigen::Transform<double, 3, 1, 0>() const+92> str x0, [sp]
0x537838 <g2o::SE3Quat::operator Eigen::Transform<double, 3, 1, 0>() const+92> mov sp, x29
x0 0x7fffffdf18 549755805464
void OptimizationAlgorithmLevenberg::printVerbose(std::ostream& os) const
{
os
<< "\t schur= " << _solver->schur()
<< "\t lambda= " << FIXED(_currentLambda)
<< "\t levenbergIter= " << _levenbergIterations;
}
ch9¶
工程会报错 opencv/viz.hpp没有¶
dpkg -L opencv //可以查看这个库到底安装了哪些文件
apt install -y libvtk5-dev
cmake -DWITH_VTK=On <path to your opence srouce>
make
make install //update the include path
ch10¶
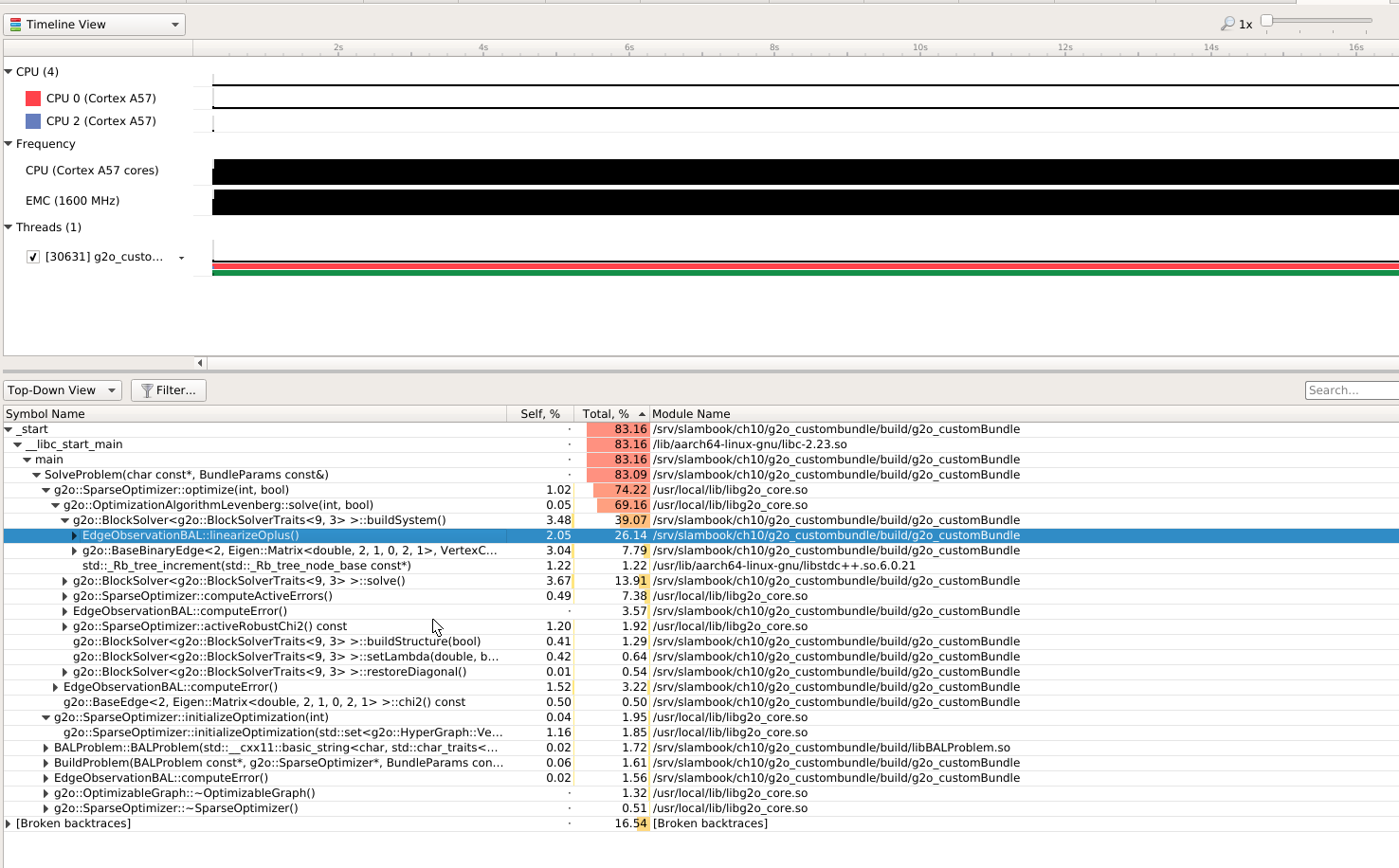
cere bundle¶
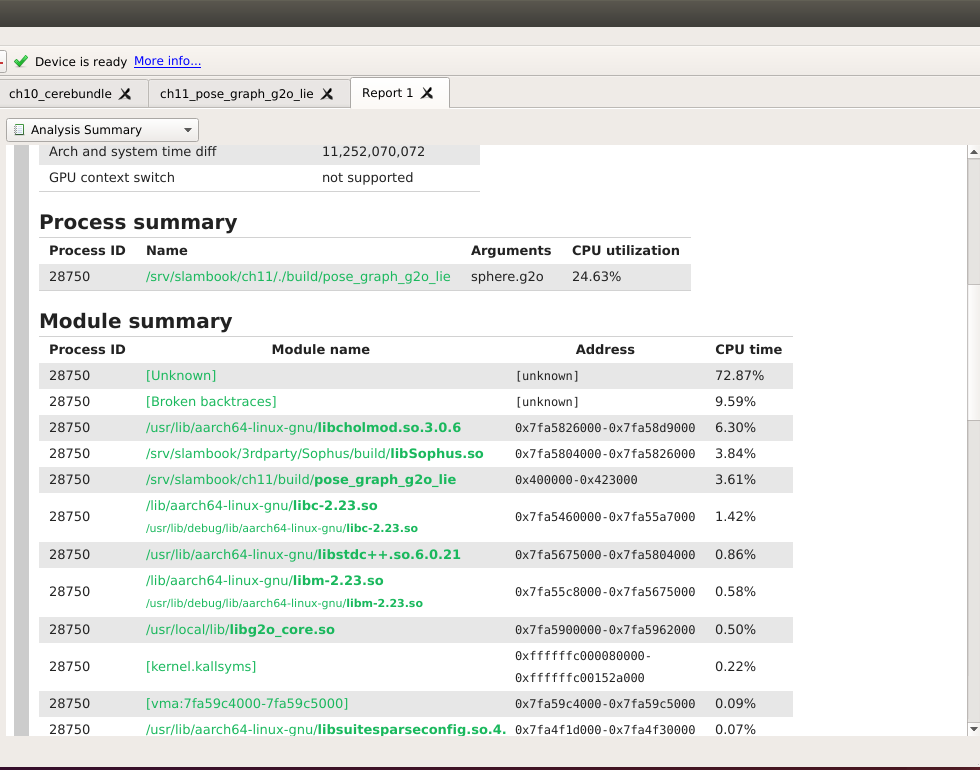
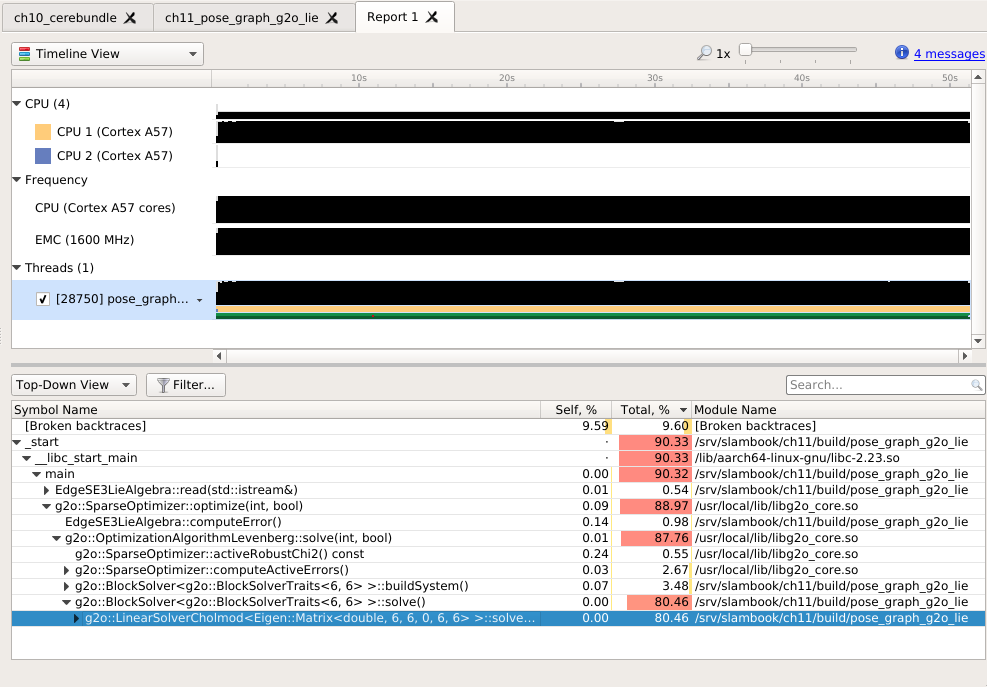
ch11¶
build error: gtsam module 为什么版本之间ARM不兼容。 https://github.com/introlab/rtabmap/issues/131, 即使都采用了相同的编译器与C++11 还是有这样的问题,很有可能是一些宏导致构成cast 链出现问题。
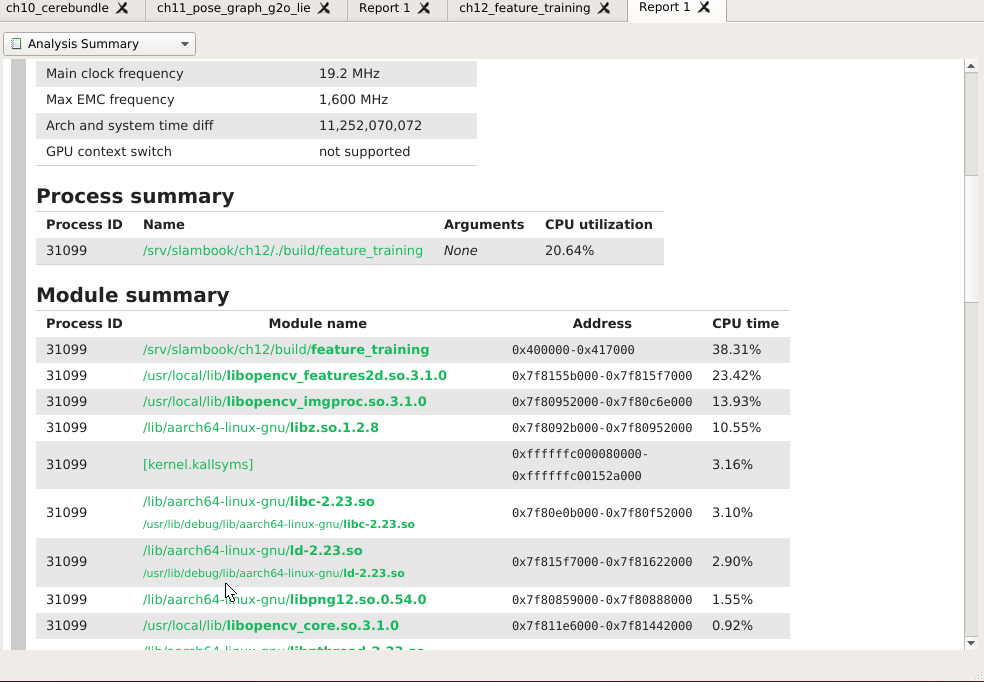
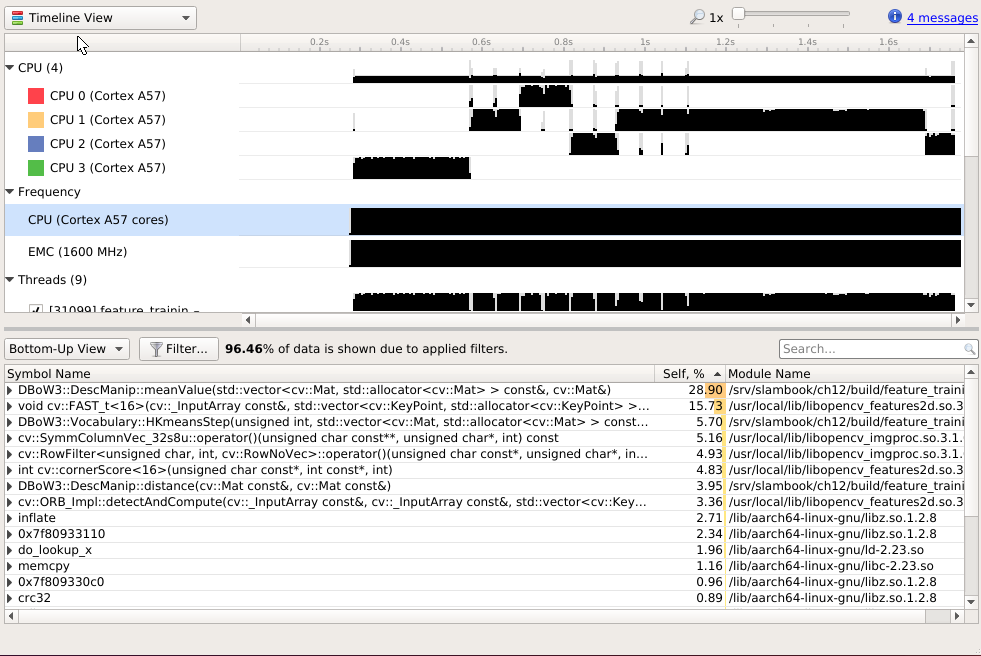
ch12¶
字典的生成,DBoW3。 字典建立的原理,
- 从训练图像中离线抽取特征
- 将抽取的特征用聚类算法把描述子空间划分成K类。
- 将划分的每个子空间,继续利用聚类分析
- 直到将描述子形成一个树形结构
struct Node {
NodeId id; //节点标号
WordValue weight; // 该节点的权重,也出现的字数除以总描述子数目
TDescriptor descriptor; //描述符
WordId word_id; //如果是叶子节点,则有词汇的id
}
DBow#的结构,
Fast Bag of Words 用AVX,SSE,MMX 指令来优化了一下,加载 比DBOW2快了~80倍, 生成字典时快了 ~6.4倍。
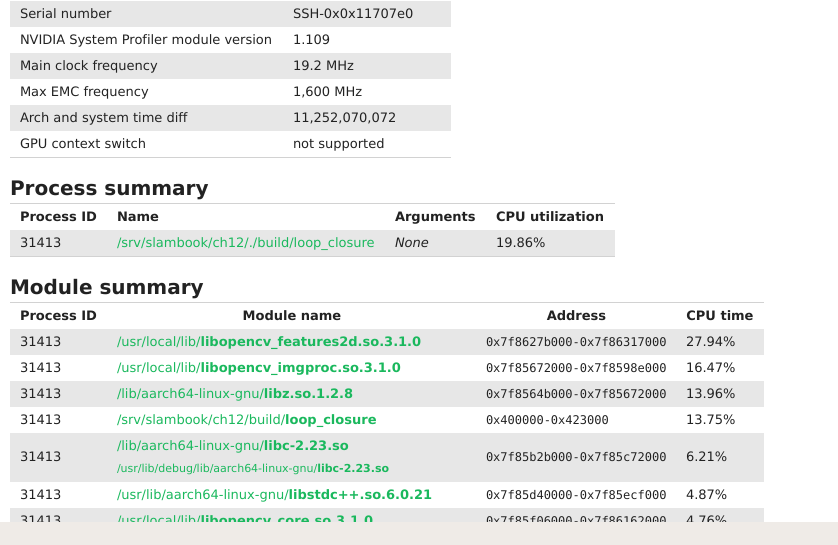
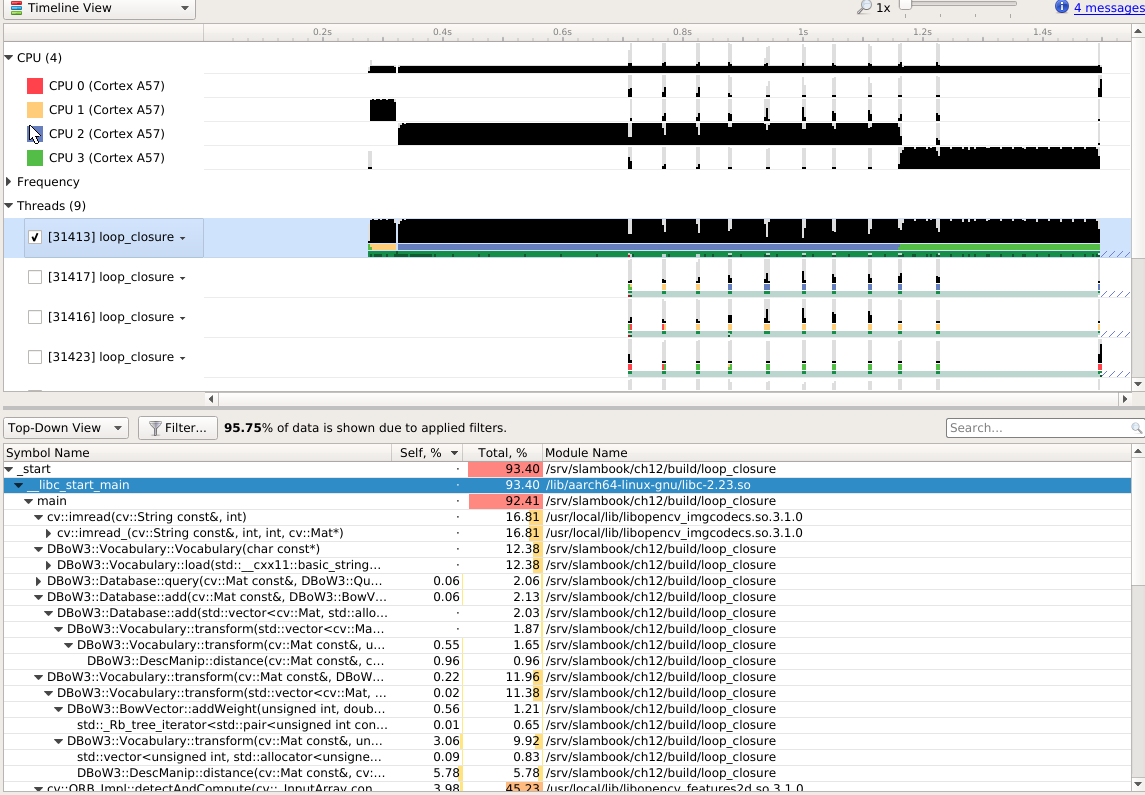
ch13¶
octomap 是可以用来展示地图,https://github.com/OctoMap/octomap 几种地图的优缺点 http://www.cnblogs.com/gaoxiang12/p/5041142.html
而简单的pcd 点运地图没有法进行导房,而采用了八叉树的模式来建立地图就像游戏地图的构件过程一样。
双目相机模型¶
利用视差来计算深度,并且 视差与距离成反比。虽然视差计算深度的公式很简单,但是视差本身的计算比较困难。 需要左右眼图像点一一匹配关系,如果计算每个像素的的深度时,其计算量与精度将成为问题,而且只有图像毋庸纹理 变化丰富的地方才能计算视差,计算还是GPU或者FPGA来计算。
RGBD-SLAMV2¶
它可以直接主动测每个像素的深度,现在发为两种
- 通过红外结构光
- 通过 飞行时间法 来测量。
而采用RGB-D 则生成采集到点云。
采用DVO的方法,直接上PCL来做了。
SLAM++
LSD-SLAM¶
LSD-SLAM is a novel approach to real-time monocular SLAM. It is fully direct (i.e. does not use keypoints / features) and creates large-scale, semi-dense maps in real-time on a laptop。 是直接法最好的SLAM,就要求传感器有深度信息,如果有每一点深度信息那叫Dense depth maps. Semi-dense Depth maps就是深度图并不并包含每一个象素点,只有移动像素的深度图.如果这些移动的点是刚体运动,这样包含了 rigid body motion+ scale. https://fradelg.gitbooks.io/real-time-3d-reconstruction-from-monocular-video/content/stereo/semi-dense.html 原理: 主要是解决地图的3D重构,直接三维的点来恢复出3D结构,例如深度图,然后用点云匹配生成三维结构.这里dense map,其实相当于图形的Depth buffer,以及Z-buffer的做法.
其中每一帧包含三大块,亮度值,深度值,以及深度方差值。
Steps: #. 参考帧上极线的计算。 #. 极线上得到最好的匹配位置 #. 通过匹配位置计算出最佳的深度。
其实上面最终都是误差的计算, #. 几何差异误差,原于相对朝向以及投影矩阵。 #. 图像差异误差, #. 基线量化误差
深度估计直接使用,直接采用卡尔曼滤波来实现。要通过profiling来快速得到其workflow. 然后结合callgraph. 三角化之后,就可以充分利用Opengl来直接化了。
视频:https://www.youtube.com/watch?v=GnuQzP3gty4&feature=youtu.be&t=22s code: github.com/tum-vision/lsd_slam 代码解读:http://blog.csdn.net/lancelot_vim/article/details/51708412 原理: http://vision.in.tum.de/research/vslam/lsdslam 优点: 不需要keypoints,features 提取,精度高,尤其是在室内这种环境. 主要是采用keyframe的方式,进行,有没有办法用skybox再加上LOD来生成一个keyframe. 一个keyframe其实是 生成两个双目frame的视频流。如何反向呢。 性能:
SVO¶
性能:近年来非常火的SLAM路线,能恢复半稠密三维,但目前的实现不太好,效率也不高 但是完全可以用OPENGL+CUDA 的汇合来实现同时在cuda中再加入DL. LSD-SLAM就是SVO的一种 主要步骤 #. 稀疏直接法, 其实就是金字塔图形里找 #. 重投影,把关键点重新投影 #. 优化 #. 重定位
ORB-SLAM¶
是目前基于特征的单目SLAM系统中效果最好的。 基于ORB特征来实现环境一致的描述。利用orb贯穿全程,并且dbow2库来进行回环检测。采用nearest neighbor方法训练出来的140多m的树状词典 所有优化问题全是基于g2o算,特征匹配直接用ORB的描述符,回环检测用BOW。并没有太多学术上的创新,论文里几乎没有什么公式。
原理:
MapPoints->KeyFrames->CoovisibilityGraph->SpanningTree 具体的流程可以参考 SLAM、orb-slam7.1 简单重构泡泡.pptx
并且采用了面向对象思想封装,把获取的图像数据装成帧。后续处理都是针对帧处理。
Frame { Image-> 存储图像数据(输入) Camera-> 存储相机的内参信息(输入) Feature-> 存储帧对应的特征数据(计算) 一对多的关系 Mat -> 存储帧对应相机的姿态 (计算) } Keyframe extends Frame; Feature { } MapPoints { } 是不是可以相当于骨骼动化的关系。Trac根据运动模型,可以opengl中的T&L变换,然后进行对比。
orb-slam得到在世界坐标系中位置 值很小 很多都是0.00几 orb-slam2中 输出的位姿 乘以初始化成功时该帧的变换矩阵 所得变换矩阵是世界坐标系到相机坐标系的转换么 SLAM-职业交流群 无题 李 code: https://github.com/raulmur/ORB_SLAM2 优点: 特征提取的匹配的计算量减少,回环检测做很好,接口丰富,对于地图密度要求不高的定位和追踪问题,ORB-SLAM是个不错的选择 缺点: #. kinect2 qhd分辨率下(960x540),默认参数,thinkpad T450,帧率<=10Hz 计算量具大。 #. 运行前要读取一个几百兆的字典——调试程序的时候比较考验耐心, 巨大的词典。目前orb使用了一个用nearest neighbor方法训练出来的140多m的树状词典。前面已经说过,这个词典在整个orb中至关重要,每次运行前必须载入至内存。在安卓手机上载入的过程长达三分钟,很恼人 #. 比较容易lost,虽然也容易找回来; #. orb 所建图非常稀疏,而稀疏的地图对于机器人下一步的应用会造成很大困难 #. 系统中有很多magic number,比如特征匹配的阈值,回环图像对比的阈值,都是经验设定,在不同场景下对应值也有所不同。这些数其实可以通过机器学习的方法学习得到 #. 采用keyframe这样的空间是不连续的。
性能: #. i7,640*480的图像中提取500orb约用时13ms,匹配精度可以接受,满足实时性要求 #. 追踪部分,平均每帧约30毫秒,基本达到了30fps。特征提取速度是非常快的,平均11毫秒左右,非常适合于实时SLAM。姿态估计稍微耗时一些,平均需要20毫秒,特别是姿态优化需要耗费16毫秒的时间。 #. 地图构建部分,平均每关键帧约385毫秒。其中生成新的点约70毫秒,Local BA约300毫秒,相对还是比较耗时的。不知道这两部分还有没有优化的空间。
- 关键点的提取与描述子的计算非常耗时。实践当中,SIFT目前在CPU上是无法实时计算的,而ORB也需要近20毫秒的计算。如果整个SLAM以30毫秒/帧的速度运行,那么一大半时间都花在计算特征点上
DSO¶
发现DSO方法的特征点提取比ORB更耗时 . SVO,
DTAM Dense Planar SLAM, OpenRatSLAM, G2O, SBA, iSAM, GPU-SLAM
- 什么时候开始的
- 每种技术优缺点
主要研究内容¶
#. 传感器的鲁棒性以及传感器融合。 1. 精度上,AR一般更关注于局部精度,要求恢复的相机运动避免出现漂移、抖动,这样叠加的虚拟物体才能看起来与现实场景真实地融合在一起;机器人一般更关注全局精度,需要恢复的整条运动轨迹误差累积不能太大,循环回路要能闭合,而在某个局部的漂移、 抖动等问题往往对机器人应用来说影响不大。
#. 复杂环境的场景理解 前面的都是基础的SLAM,只有”定位”和”建图”两件事。这两件事在今天已经做的比较完善了。近几年的RGB-D SLAM[5], SVO[6], Kinect Fusion[7]等等,都已经做出了十分炫的效果。但是SLAM还未走进人们的实际生活。为什么呢? 因为实际环境往往非常复杂。灯光会变,太阳东升西落,不断的有人从门里面进进出出,并不是一间安安静静的空屋子,让一个机器人以2cm/s的速度慢慢逛。论文中看起来酷炫的算法,在实际环境中往往捉襟见肘,处处碰壁。向实际环境挑战,是SLAM技术的主要发展方向,也就是我们所说的高级话题。主要有:动态场景、语义地图、多机器人协作等等。 http://www.cnblogs.com/gaoxiang12/p/4395446.html 非特点SLAM, 动态环境,多机器人协作,长时间SLAM。 语义信息。 拓扑/网格地图。 #. 复杂背景下慢速的目标的识别,(怎样识别,识别哪些?) #. 动态场景运动分离技术 #. 主动SLAM,SLAM+ Exploration.
#. SLAM 的计算需求巨大的,现有算法达不到实时性的要求。 效率上,AR需要在有限的计算资源下实时求解,人眼的刷新率为24帧,所以AR的计算效率通常需要到达30帧以上,但是要想流畅就得每秒60fps 也就是小于16ms,如果想没有眩晕,要至少达到90fps也就是要11.111111ms.; 机器人本身运动就很慢,可以把帧率降低,所以对算法效率的要求相对较低。 3. 配置上,AR对硬件的体积、功率、成本等问题比机器人更敏感,比如机器人上可以配置鱼眼、双目或深度摄像头、高性能CPU等硬件来降低SLAM的难度,而AR应用更倾向于采用更为高效、鲁邦的算法达到需求。
- 研究利用传感器神经网络与回声状态状态网络 解决鲁棒性与精度的问题。
- 研究利用3D重构技术来实现地图的重建与深度学习来解决复杂场景理解。
- 研究利用LLVM来实现全时优化来解决算法的效率,利用GPU与FGPA来提供的计算能力。
由于SLAM 算法的本身的复杂性,以及硬件平台的多样性,开发难度大,需要直接使用现有大量的成熟的库来加快开发速度。例如对于eigen3矩阵运算库,Ceres 优化库,以及OpenCV,PCL等大量库使用。可以提高开效率。但是对运行效率很难保证,实时性更无从谈起。更加大的算法仿真的效率。需要用大量的分析优化工作来运行效率。 LLVM是基于SSA的能够提供编译时期,链接时期,运行时期,闲置时期全时优化的动态编译技术。利用利用LLVM 的SSA形式的IR来分析数据依赖关系,删除无效代码,实现循环的展开,尽可能并行化,根据硬件资源特性与限制最大化利用硬件资源例如寄存器与高速的cache,ARM的NOEN指令,以及GPU的SIMT(Single instruction Multiplethread)技术。大大提高算法的计算效率。同时利用LLVM本身指令信息的完备性,能够对于进行硬件模型的精确化分析。 #. GPU加速的SLAM